Everyone (including Snoop Dogg) should have their own databases.
To start building our personal DNA (Data and AI) department, we must first own the data. Nowadays, data are usually not owned by ourselves as the users, but by the tech giants as the service providers. It's the time to take our data back. The very first step is to create a self-hosted database.

What is a database? (wiki definition) #
"A database is an organised collection of data (also known as a data store) stored and accessed electronically through the use of a database management system. Small databases can be stored on a file system, while large databases are hosted on computer clusters of cloud storage."
Why a database? (database vs. gsheet/excel) #
Many people without technical background are comfortable with using excel or gsheet. They have two drawbacks:
- The user interface is friendly but it also at the same time limits the performance when the data becomes huge. Imagine loading 10 million rows of data into your excel or gsheet.
- They have their own ecosystems, which means the I/O interface is closed in their ecosystem as well. For example, if you want to visualise the data from a database, since the interface is universal and open, you can visualise them with many different tools. On the other hand, if you want to visualise the data in an excel file or in a gsheet, your options are quite limited.
Why a database? (database vs. Python Pandas) #
Python is popular nowadays. People might ask why they need to use a database while they can use for example Pandas in Python to process the data.
Databases are designed for persistent data storage and they are able to handle large volumes of data efficiently, even when the data exceeds the available memory. Data stored in a database remains there even if your Python program or computer crashes.
Pandas in Python, on the other hand, is primarily an in-memory data manipulation library. Data loaded into pandas DataFrames is stored in memory, and it's lost when your program exits. It's not suitable for long-term data storage or sharing data across multiple applications or users.
Types of database #
The most common types include relational databases and NoSQL databases. The former store data in tables with rows and columns. They use a schema to define the structure of the data. The example include PostgreSQL, MySQL, etc. NoSQL databases are designed for flexibility and scalability and can handle unstructured or semi-structured data. The most well-known example is MongoDB, which stores data in the JSON format.
How to host a database by yourself? #
Hosting a database by yourself is way easier than you could imagine. There are just a couple of steps. Let's go through an example where we host PostgreSQL on our local laptop.
Prepare two files. Name one file as docker-compose.yml and add the following content.
version: '3.9'
services:
db:
image: postgres
env_file:
- database.env
volumes:
- database-data:/var/lib/postgresql/data
ports:
- 5439:5439
restart: unless-stoppedName the other file as database.env and add the following content.
POSTGRES_USER=snoopdogg
POSTGRES_PASSWORD=dropitlikeitshot
POSTGRES_DB=doggystyleStore these two files in the same path and then run the following command line at that path. Make sure docker (including docker-compose) has been installed on your system before running it.
docker-compose upLet's assume you set up everything on your local laptop. Then you should be able to access to your database through localhost:5439, using the username, password and database name specified in the database.env file.
How to query from a database? #
Unfortunately, if you enter localhost:5439 as a URL into your browser, you won't be able to access anything. A common interface is a database client (or IDE), which is the graphical user interface where you can connect the database and query the data. One of the most famous cross-platform database clients is DataGrip, which supports almost all kinds of databases. However, it's not free. I use DBeaver (the Community version) for my personal projects. It's also cross-platform and quite powerful.
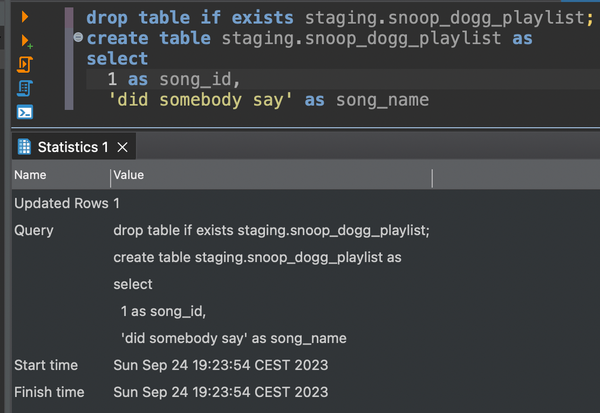
After setting up the database connection in DBeaver, you can just freely create any table as you want in the database by writing SQL. For example, let's just create a table called snoop_dogg_playlist in the staging schema.
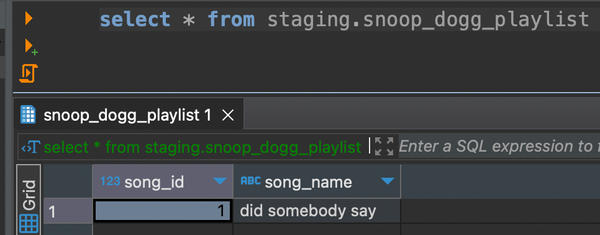
Fianlly, you can write another SQL to query from this table you just created.
How to ingest data into your database? #
It's almost impossible to create all your data by manually writing SQL like CREATE TABLE XXX AS SELECT ... every single time in DBeaver, not to mention you have to do it row by row for each table. I usually don't do the data ingestion part in this way.
Remember one advantage of database is the universality of its interface. You can easily connect to a database in Python or R, with certain libraries. Even though we have mentioned Python Pandas might not be the best for long-term data storage, but it can do a great job manipulating the data from external sources and then writing them into a connected database, using the to_sql api.
Just imagine you can run a Python script scraping for example your health data from your smart watch on a regular basis and the data will be regularly inserted into the database, so that you finally own such data in your own database.